
Paper Reading: Embodied AI 5
从一些 Embodied AI 相关工作中扫过。
EO-1#
偏向于 OpenVLA-like 的 co-training VLA
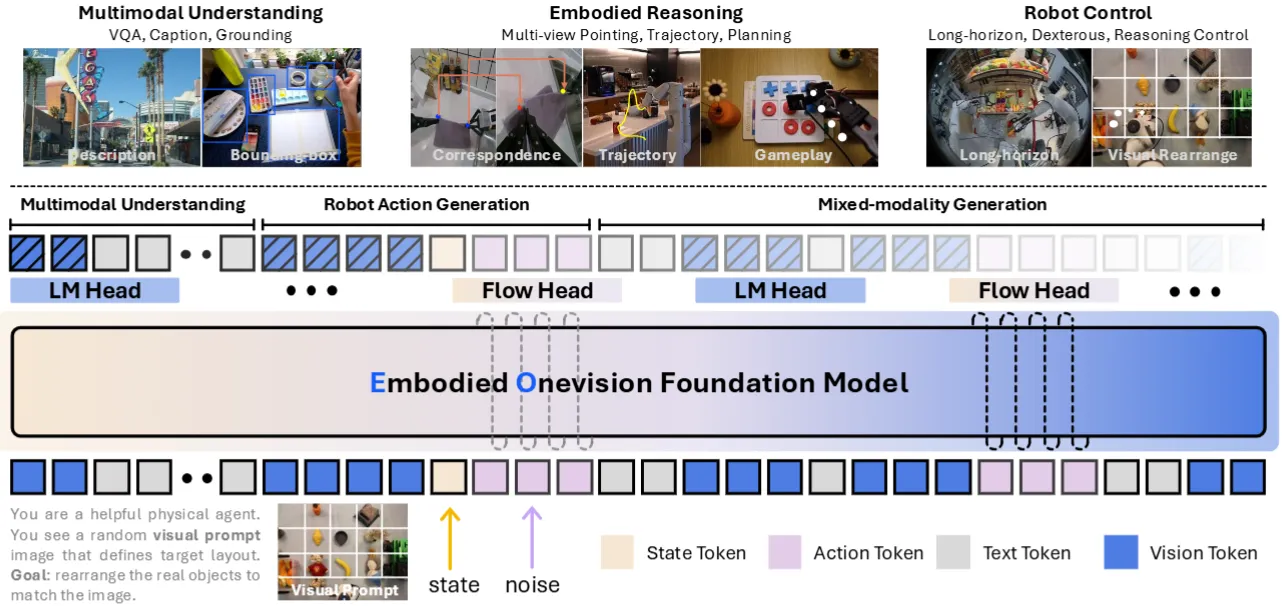
EO-1 是一篇很大的工作,包括了大量的实验,以及基于目前开源数据训练的一个模型。本身其实论文的篇幅比较长,乍一看也是十分的专业,但是其实感觉一些内容写得非常不清楚,在这里给一个简单的理解。
本身 EO-1 包括一个从 Qwen2.5VL 初始化的 Transformer 主干,支持 VL 以及 state, noisy action 的输入,其中 action 是直接过的 projection layer。然后 EO-1 支持两种不同的输出,也就是文本以及 action。其中文本就是直接使用 detokenizer 进行输出,使用 AR Loss;而 action 则经过一个很小的 Head 之后使用 FM Loss。本身数据就是交错的格式,论文中讲的非常乱七八糟的内容其实本身没有任何的含义,就是将 N-1 的 history 段中都是干净是数据,N 的是 noisy action,然后对 N 来进行 one-step 的 FM。
本身论文还是在数据上做了一些构造,定义了不同类型的推理,但是在这方面在实验上来看,最后实验中展示的推理也是后训练进去的(也就是只使用特定任务上的数据进行训练任务分解,而不是模型在预训练上就具有这样的能力),并没有意料之外的 Feature。而其中对于 Action 的部分,可以说是用了一个很小的 Action Expert,肉眼可见的可能在 VLM 的 Transformer 中带来一些 conflict,这里面也没有着重去解决。综上所述,其实算是比较中规中矩的工作,出于论文写作的角度,让人看得云里雾里,还是不算很喜欢。
OpenVLA#
OpenVLA 的原始工作
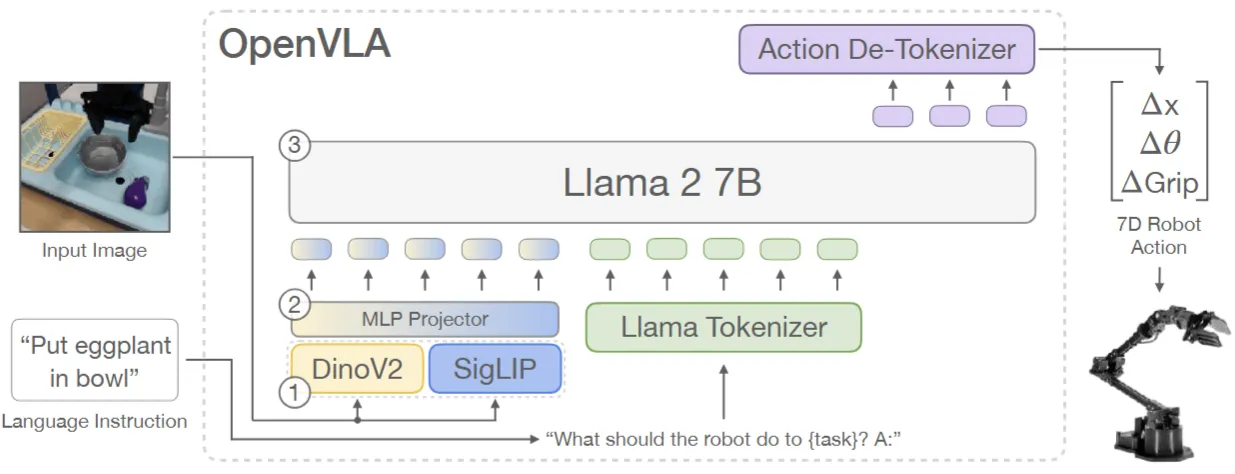
OpenVLA 的原始工作,如今补上。OpenVLA 继承了 RT-2 的思想,是十分经典的范式。简单来说,就是使用 Transformer 进行 Fusion,将图像、语言作为输入,输出动作 token,再过 Action detokenizer 得到动作。
本身 OpenVLA 的 limitation 也非常明显,面对如今的 Co-training 需求,OpenVLA 选择使用最不常见的 256 个 Token 作为 Action token,这使得 OpenVLA 在面对灾难性遗忘的同时,还面临十分极致的双峰分布学习问题,也就是在学习 VL 的时候,模型需要尽可能少输出这些 Token,而学习 Action 的时候,模型需要完全输出这些 Token。这一问题使得某种程度上,OpenVLA 的 Llama2 可能更多地作为一个 VL Fusion 的模块,而其中的先验知识可能难以被充分利用。即使如此,OpenVLA 也是成为了奠基性的工作。
OpenVLA-OFT#
若干 Trick 对于 OpenVLA 的改进
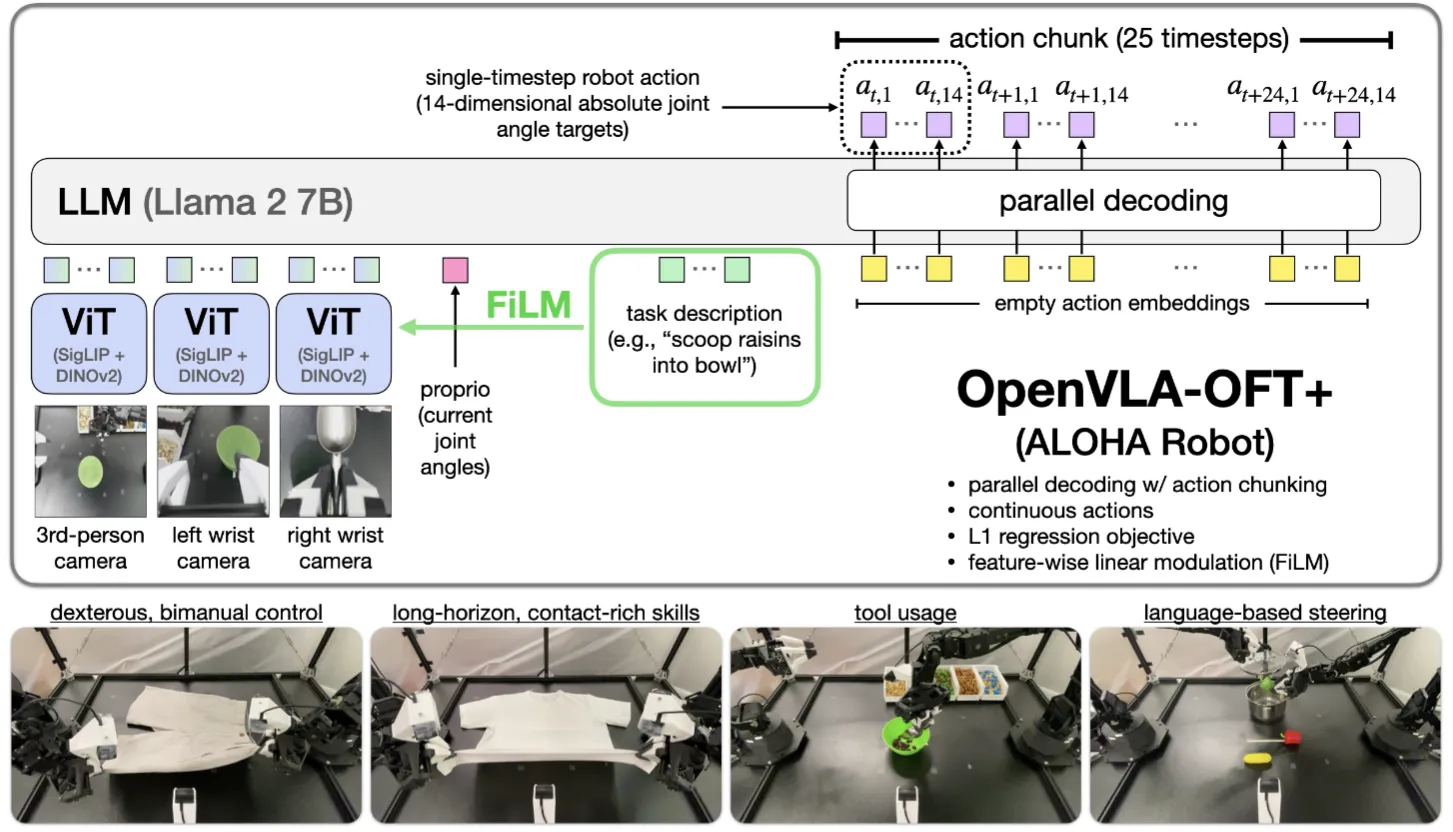
OpenVLA-OFT 可以说是在 OpenVLA 上面进行了若干的改进。主要包括几点,第一个是使用双向注意力进行并行解码,从而同时输出全部的 Action,这样全部的推理都变成了一步,也就是你的机器人有 N 维,就可以声称 N 倍加速。同时输出也改成了一个 MLP,之后输出连续动作,这在某一方面从而变成了使用 hidden state,避免了双峰分布的学习,并且可以使用 L1 损失,可以说非常的简单直接但是有效;第二个是 FiLM,使用 FiLM 来将 Language 的信息直接注入到 Image encoder 中,从而增强对于 Language 的感知。本身可以说广受认可而且确实不错,可惜 OpenVLA 的 Codebase 确实不太好,不然可以说是非常好的基石了。
Robix#
交互、推理以及规划的 Embodied VLM
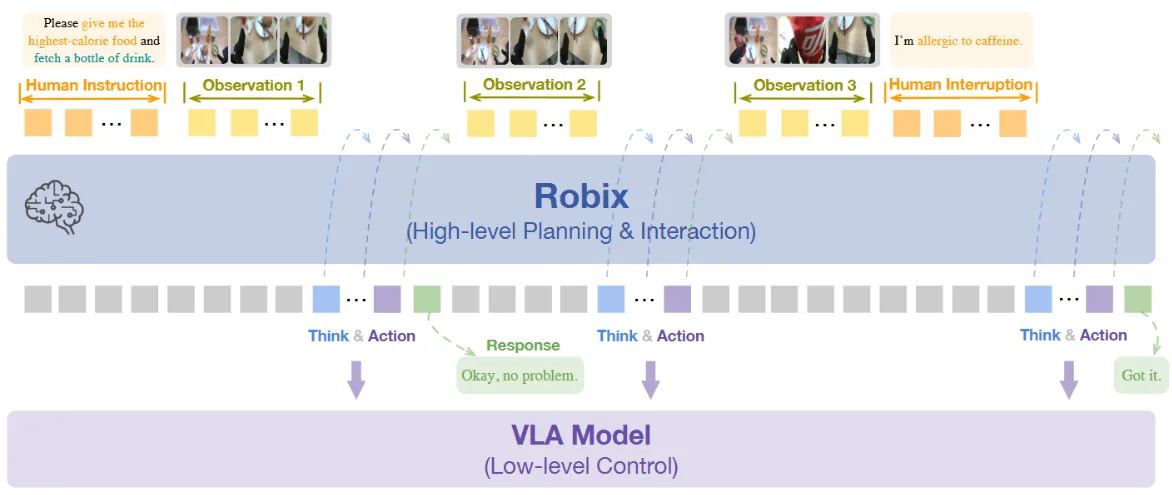
虽然说标题里面说 A Unified Model,不过看上去其实只是一个单纯的 VLM Planner 而已,只是支持了不同的 VL 输出情景。本身比较简单,就是合成了一些数据,然后进行了继续预训练、SFT 以及强化学习。算是比较经典的套路。这里面值得一提的是其中 VLM 输出的 Action 应该是 primitive action,本质上也是 Text 输出。之后双系统给到下游的 VLA。在这里比较搞的是,这里面有一组给出的 Real World 的 Embodiment 部署是用人来代替的 VLA,比较神秘。
FLOWER#
使用中间层作为中间表征并且用共用参数 AdaLN-Zero 作为 Action Expert 的 Pi-like 范式
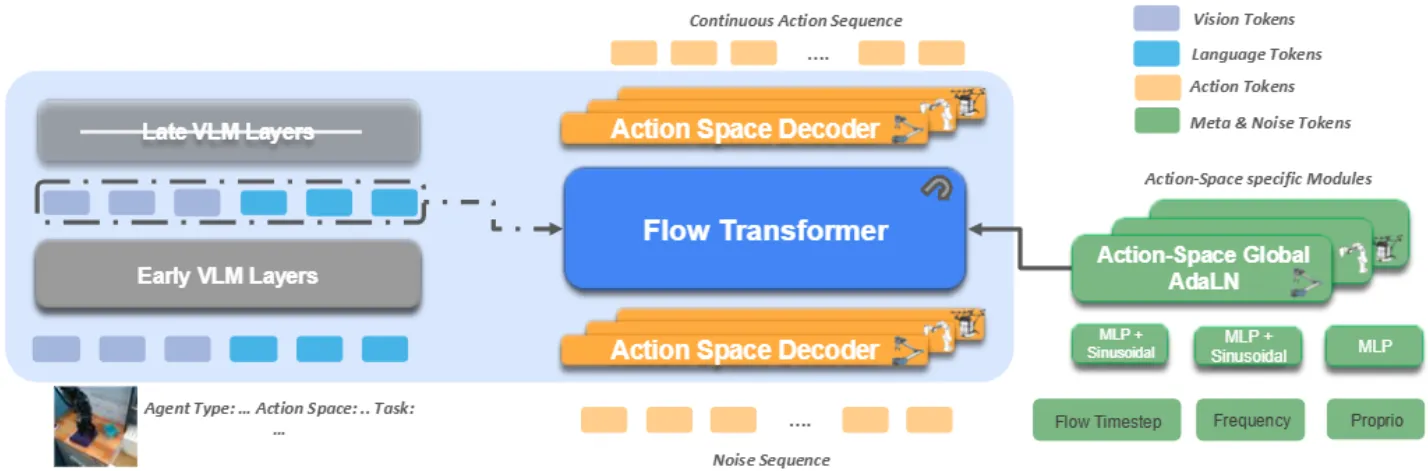
FLOWER 使用 Transformer 的中间层的输出,同时让 Diffusion 的 AdaLN-Zero 的参数都共享。对于不了解 Diffusion 具体操作的读者,可以理解为 AdaLN-Zero 是一种类似于 FiLM 的内容,通过修改 LayerNorm 的参数来对于模型进行调制,是目前比较常用的添加 Condition 的做法。本身其实思想都比较通用了,比如说中间层,似乎 GR00T 已经是类似的操作了。总体来说中规中矩。
F1-VLA#
VLM - World Model - Action Expert 的 MoT Pi-like 的范式
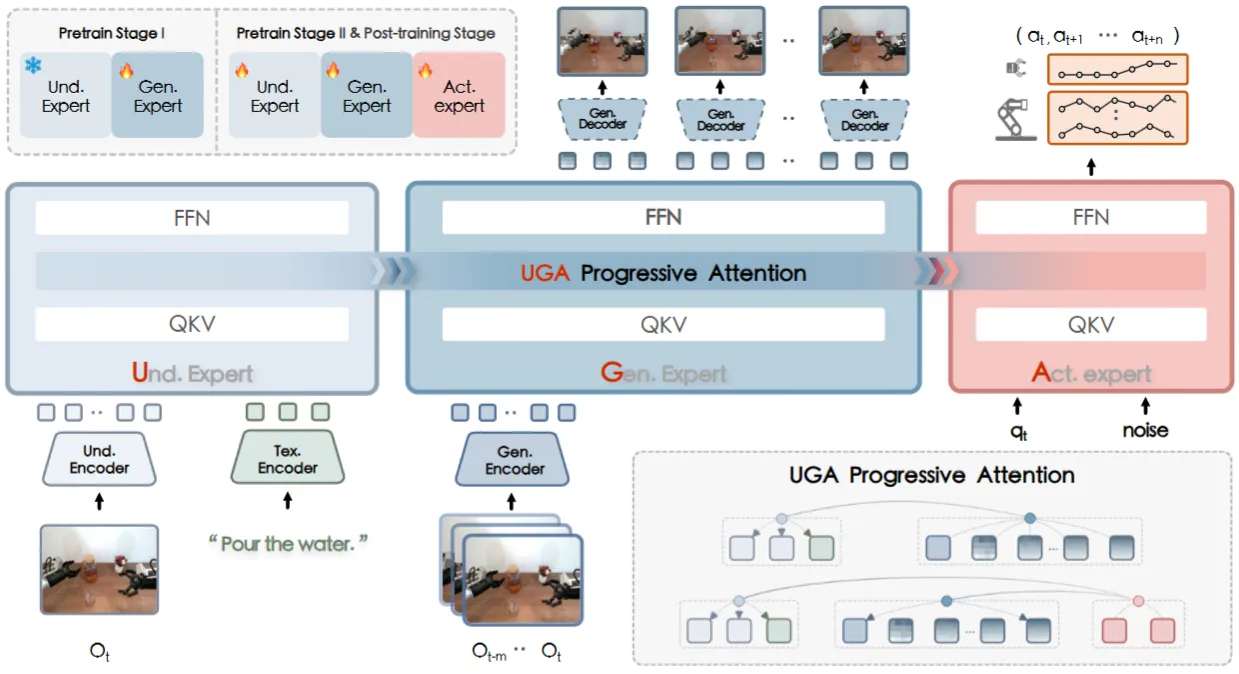
F1-VLA 可以说还是做了非常不错的探索。Pi-like 直接使用了 VLM 以及 Action Expert 进行 MoT,也就是直接使用 VL Data,那么另一条路线似乎也是显然的,就是如何使用 World Model 来吃 Video Data。
F1-VLA 可以说是直接将这些东西整合在一起了,把 VLM, World Model 以及 Action Expert 来同时做 MoT。F1-VLA 带来的问题是,其将 MoT 描述为了一种因果关系,即,VL 带来理解能力,World Model 紧接着预测未来,最后 Action Expert 输出具体动作。虽然本身是 MoT,其实无所谓这些东西,但是如何进行这些数据和模型之间的 Balance,依然是一个严重的问题,但是目前看上去模型只在 VLA 数据上进行了训练,虽然经过了所谓的对齐,不过对于如何吃下更多的数据没有进行充分的探索。
总体来说还是很不错,但是值得后续的探索,值得一读。
VLA-Adapter#
使用 Bridge Attention 作为连接方式的 Pi-like 范式
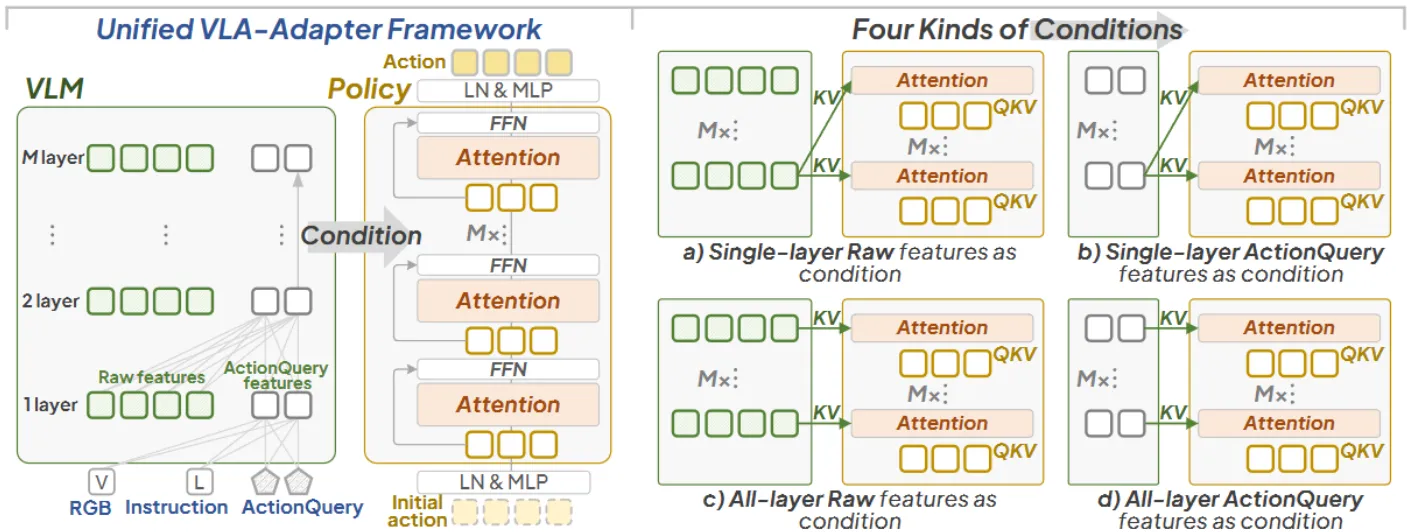
VLA-Adapter 的主图如上,主要还是总结了之前的 VLA 的范式,这里是从 Pi-like 的角度出发,思考如何从 VLM 给 Action Expert 提供 Condition。VLA-Adapter 本身的范式其实是图中的 C 类型,但是使用的就不是常规的添加 Condition 的方式,而是使用了他们自己设计的 Bridge Attention 的连接方式。
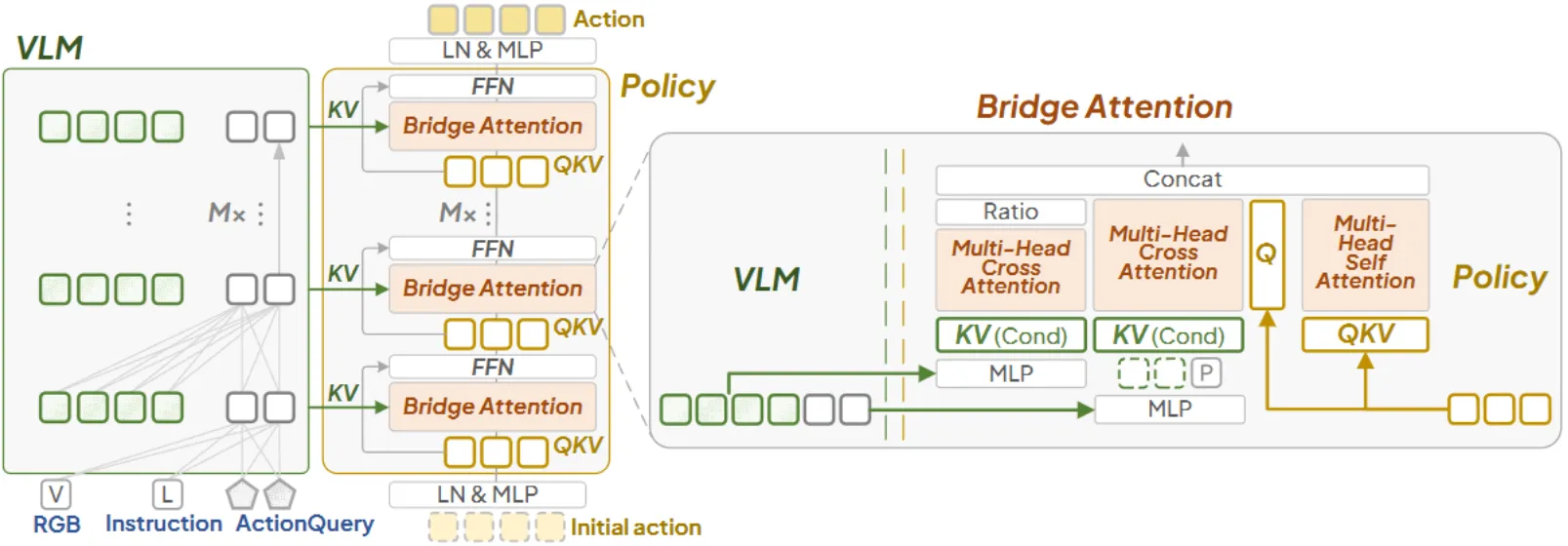
Bridge Attention 的结构如上,在这里并不主要关注具体实现,本身的思想还是尽可能的如何更多地把 Condition 施加过去,感觉看上去效果还不错。Bridge Attention 本质上并非 DiT,而是直接从 Initial action 进行一次直接的预测。总体来说还可以,但是其实讲实话,并没有非常多的 insight。Bridge attention 阐述了施加 condition 的重要性,但是更多地证明为什么是这个结构,并没有很多有效性相关的阐述。
SimpleVLA-RL#
使用直接的 online GRPO 对 VLA 进行强化学习
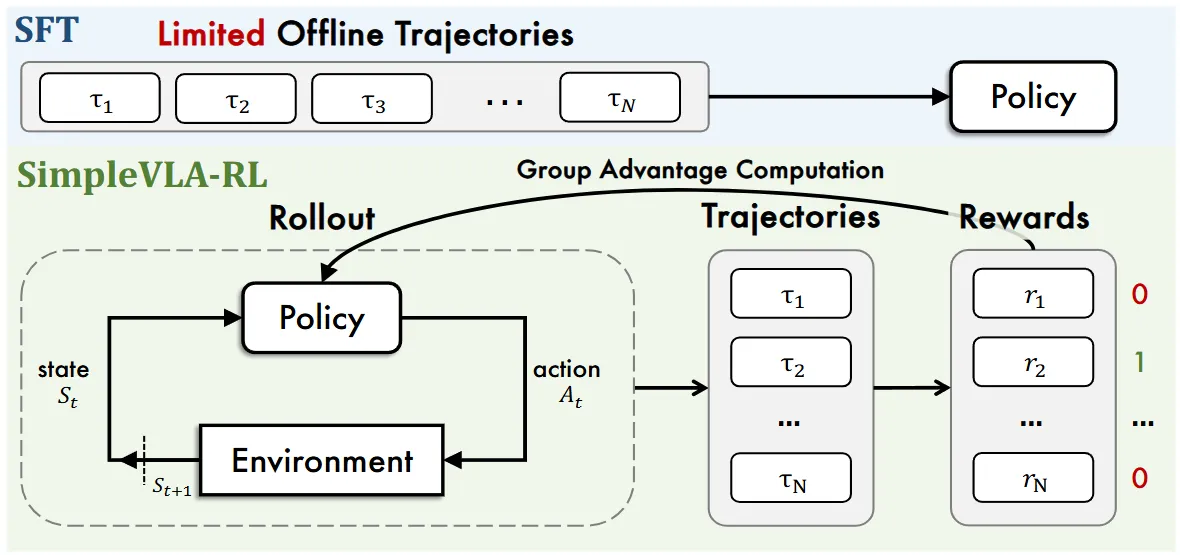
SimpleVLA-RL 本身是使用直接的 online GRPO 对 VLA 进行强化学习,本身比较简单,但是效果还不错。其中其实有不少的细节也是值得品味的,比如说对于 GRPO 在 VLA 里面的改进,类似于动态采样或者 rollout 的时候增大采样温度。对于想要做 VLA RL 的读者来说值得细品。以及其中带来的一些有趣的 findings,也就是论文中说的 Pushcut,大概就是说因为 Goal 的反馈,导致模型在基础初始化的 Pick and Place Skill 的基础上自己学会了使用 Push 动作来解决任务,算是确实是 RL 的优点之一了,也就是 RL 可以超越数据本身自主探索。
RynnVLA-001#
I2V Model Pretrain 的 WM VLA
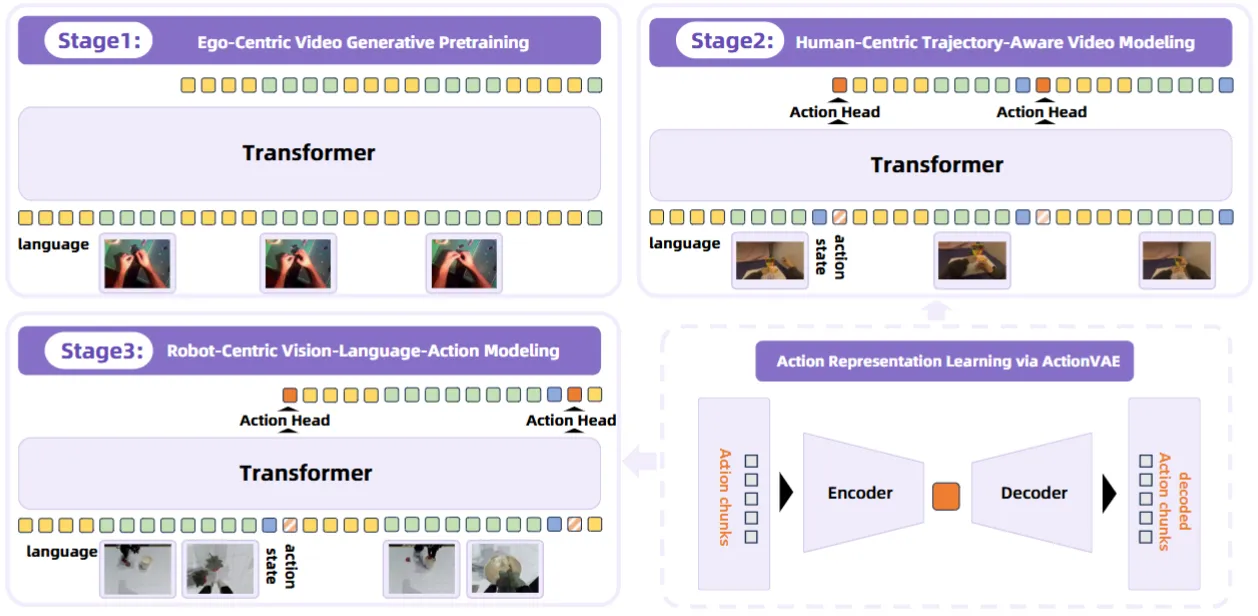
RynnVLA-001 本身是使用 I2V Model Pretrain 的 WM VLA。本身思路还是比较简单的,主要就是直接用 Transformer 训练一个 I2V 的模型,之后在 Ego 数据集上训练 Human action 的 action model,之后最后用 Robot action 来进行 post-training。问题其实也比较显著,就是其实大家对于 World Model 的关注点还是,因为其可以显式地展示很多 OOD 的泛化能力,因此这些能力如何,以及如何将这些能力 transfer 到 VLA,是否有效等。RynnVLA-001 的实验在 SO100 机械臂上进行,相对比较 Toy,也只说明了性能上的内容,感觉还是会稍微差些意思。不过本身这套流程还是没问题的,期待后续工作吧。
Evo-0#
将 VGGT 的 hidden state 和 vision encoder 进行 fusion 的 pi-like VLA
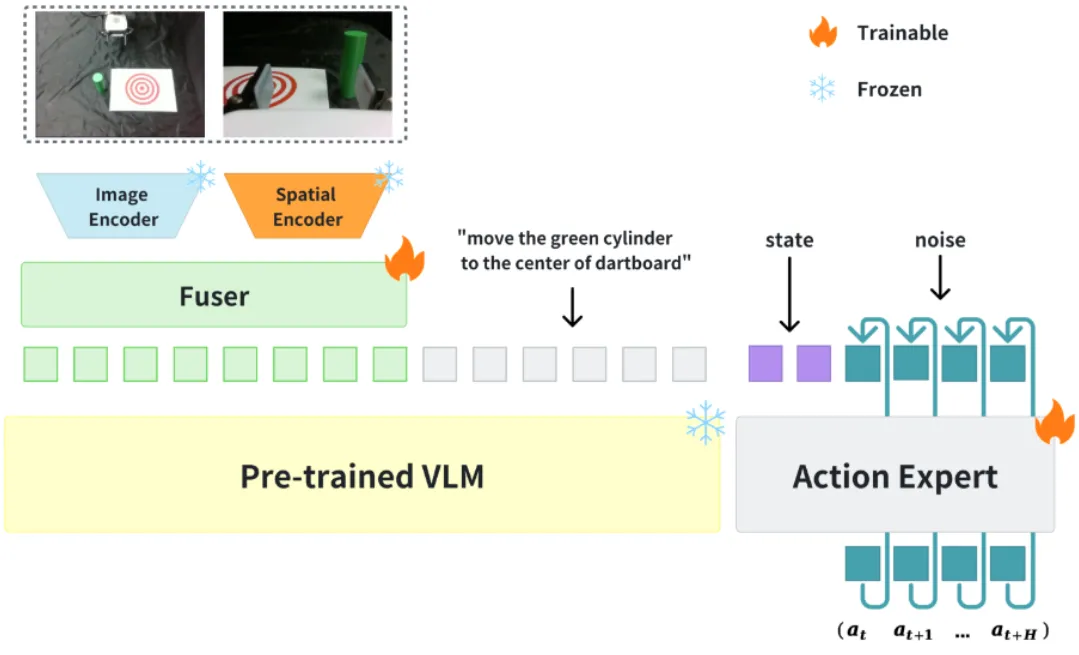
Evo-0 的内容如 tldr 所示,就是将 VGGT 的信息作为 spatial encoder 加入了到了 Pi-0 里面,从而增强了 VLA 的 spatial 能力。本身模型是直接基于 Pi-0 改的,所以别的内容也没有很多的变化。模型本身在一些精细操作上似乎性能不错,但是实验本身的次数也比较有限,说服力不加。总体来说是一篇意料之中的论文,相似的思路或许可以在他们的 codebase 上进一步迭代。
Imagine2Act#
生成 Goal 的 Image 以及 Depth 以及 Transformation info 作为 Condition 的 DP
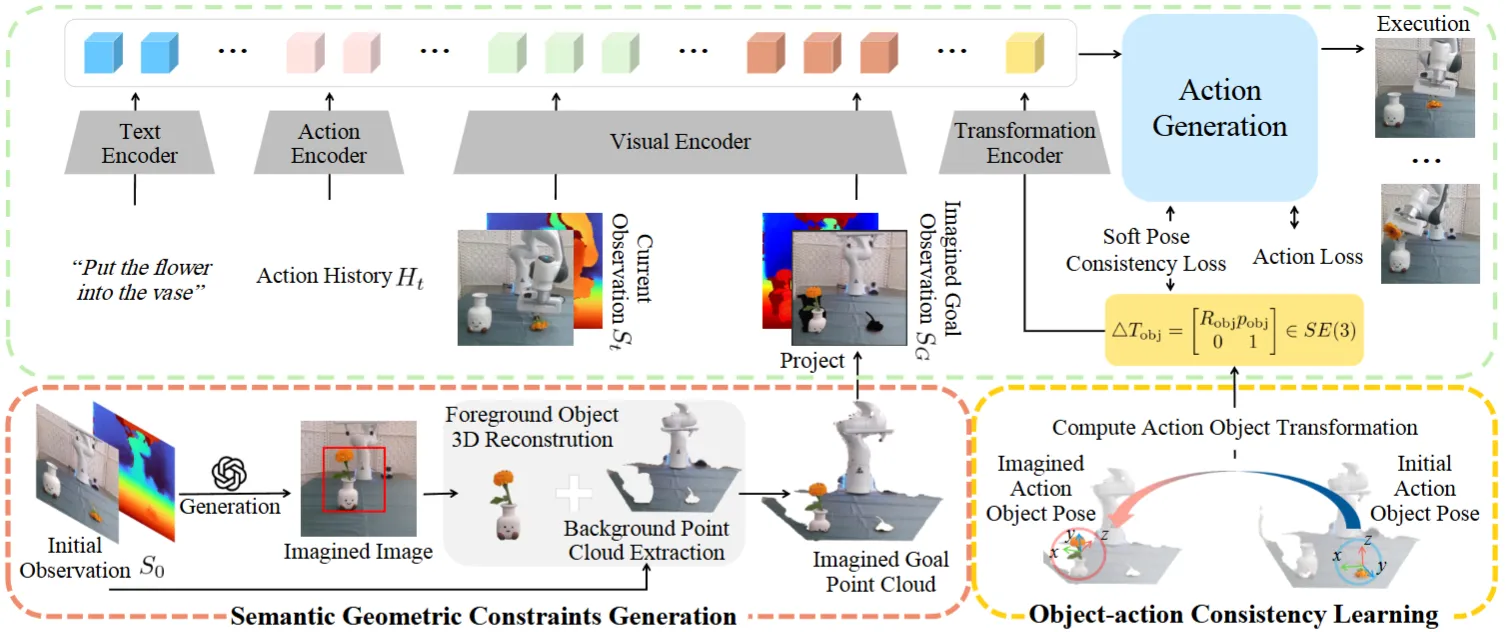
Imagine2Act 本身似乎还是有些古典,在 DP 上进行了一些探索,主要负责解决物体重排的任务。本身的思路如图所示,借助了类似于 4o-image 之类的模型,来生成模型的 Goal Image,并且通过 SAM 以及变换来得到 Goal 的 Depth,同时计算 Transformation info,分别进行 encode 然后作为 condition 输入到 DP 中。总体来说思路还是比较直接的,问题主要在于这种过于 modular 的方法并不能 scalable,而且会引入多余的不稳定性。
HDMI#
模块化设计 Reward 并且进行全身控制
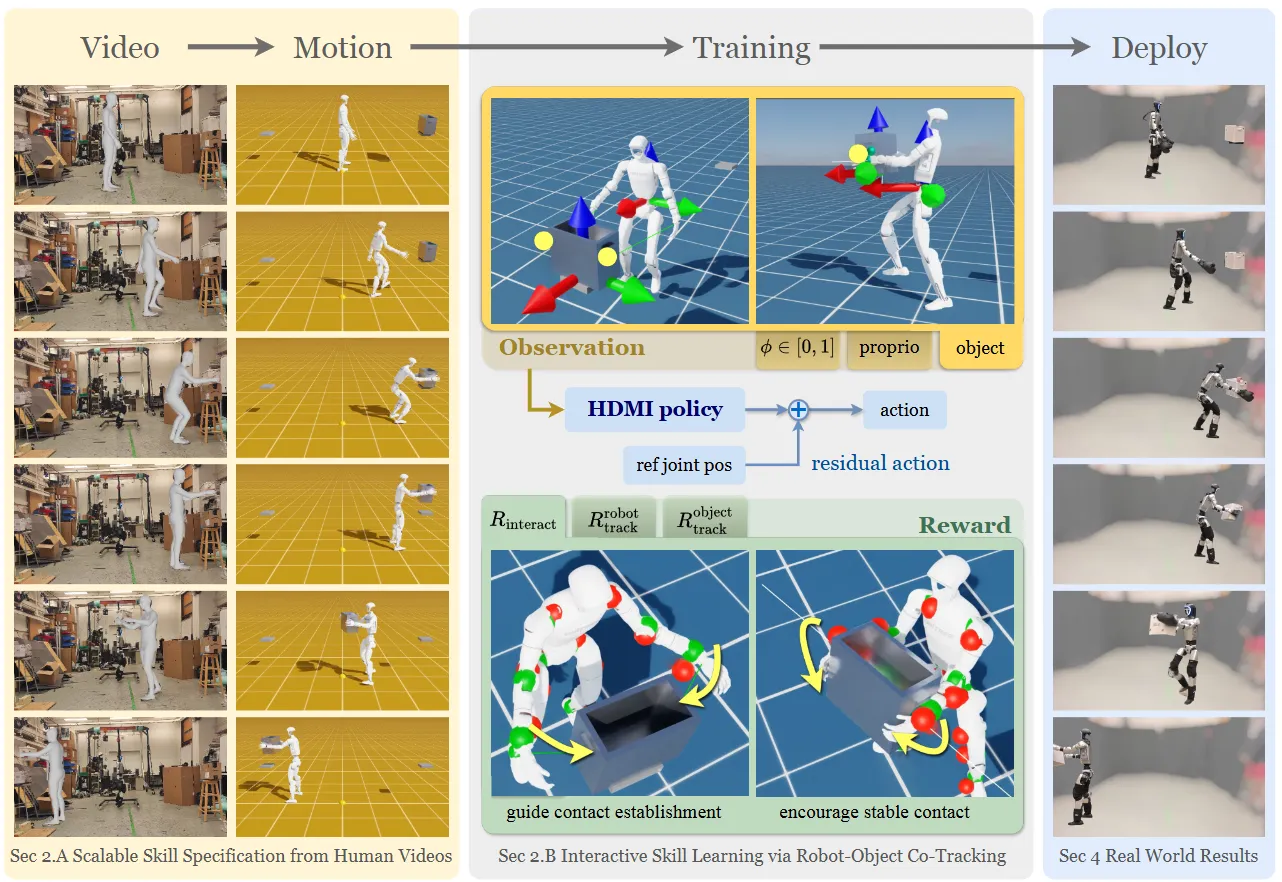
HDMI 本身比较直接,如图中所示,其实也就是整合了前人的几个工作。首先从视频中恢复人体数据以及比如说 articulation 或者别的物体的信息;然后根据这些 Goal 来去进行 RL,涉及了一些细节,比如设置接触点的 Reward 以及使用相对的 joint 去控制。本身的比如说 RL 以及其他的内容都是 follow 之前的工作,整体大概就是这样,大概是一种整合性质的工作,从效果上来看还是可以 Sim2Real 的,也算可以了。感觉 Locomotion 这种偏向传统 robotics 的可能其中的控制相关的细节很多,相关的读者可能会很西湖区按。不过从 CVer 的角度来看,确实似乎没有过多的启发。
World4RL#
使用 World Model 提供 Sim 以及 Reword 的 RL
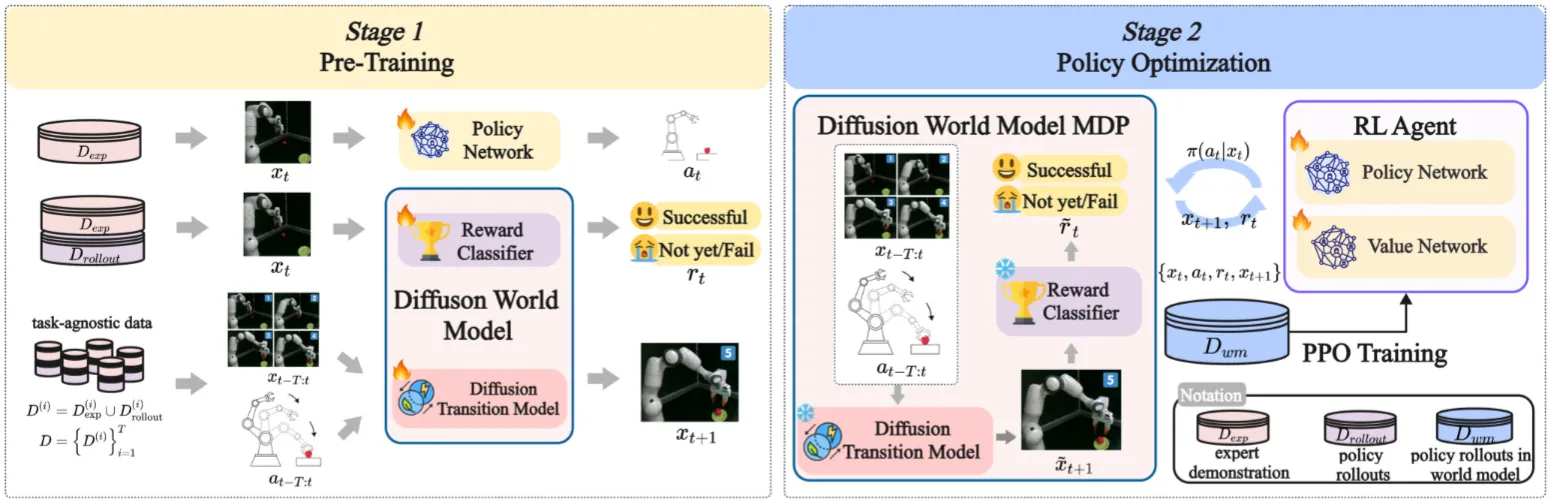
World4RL 本身讨论了一个很不错的话题,也就是使用 World Model 进行 RL,毕竟本身 Simulator 能够进行的 RL 还是不太 Scalable 的。本身的做法也是比较简单,首先需要训练一个可以根据 Action 来 Predict next frame 的 WM,然后再训练一个 Rewarwd Model,World4RL 本身也是按照这个思路进行的。本身使用 UNet 来训练 WM,使用 one-hot 来编码 action,然后在任务无关数据上训练。之后用一个 ResNet-18 + 分类器的模型作为 RM,在任务相关数据上训练。本身可以说思路不错,在有了 WM 和 RM 之后就可以正常的训练 Policy 了,不过确实模型选择的都比较古老,而且完全不是使用的 Scaling 的数据,所以其实效果也不是很显著,没有展现这种范式理论上的通用性。相关思路值得参考,但是实现上确实感觉还是仓促了很多。
Universal Manipulation Interface#
UMI 开山之作,经典的机械结构设计

UMI 其实绝对来说是类似于机械的结构设计。本身的核心思路其实比较简单,也就是设计一种类似于通用的夹爪来统一全部的数据,于是 UMI 出现了,可以让一切夹爪看上去都是一样的。其中其实相对聪明的一点还是在于,本身 UMI 的运动数据不是从机械臂里面 FK 获得的,而是通过 IMU 获得的,这使得无论是什么机器人,UMI 的精度以及尺度都是一致的,而且也比较高。甚至 UMI 其实是可以直接手持来采集数据的。后续 UMI 类似的设计也有很多 Follow,虽然其实感觉在这个基础上设计自己的 UMI 反而破坏了社区,导致了数据的分岔,但是总的来说这个想法还是十分有意义的。
FastUMI#
UMI 改版 + 数据集
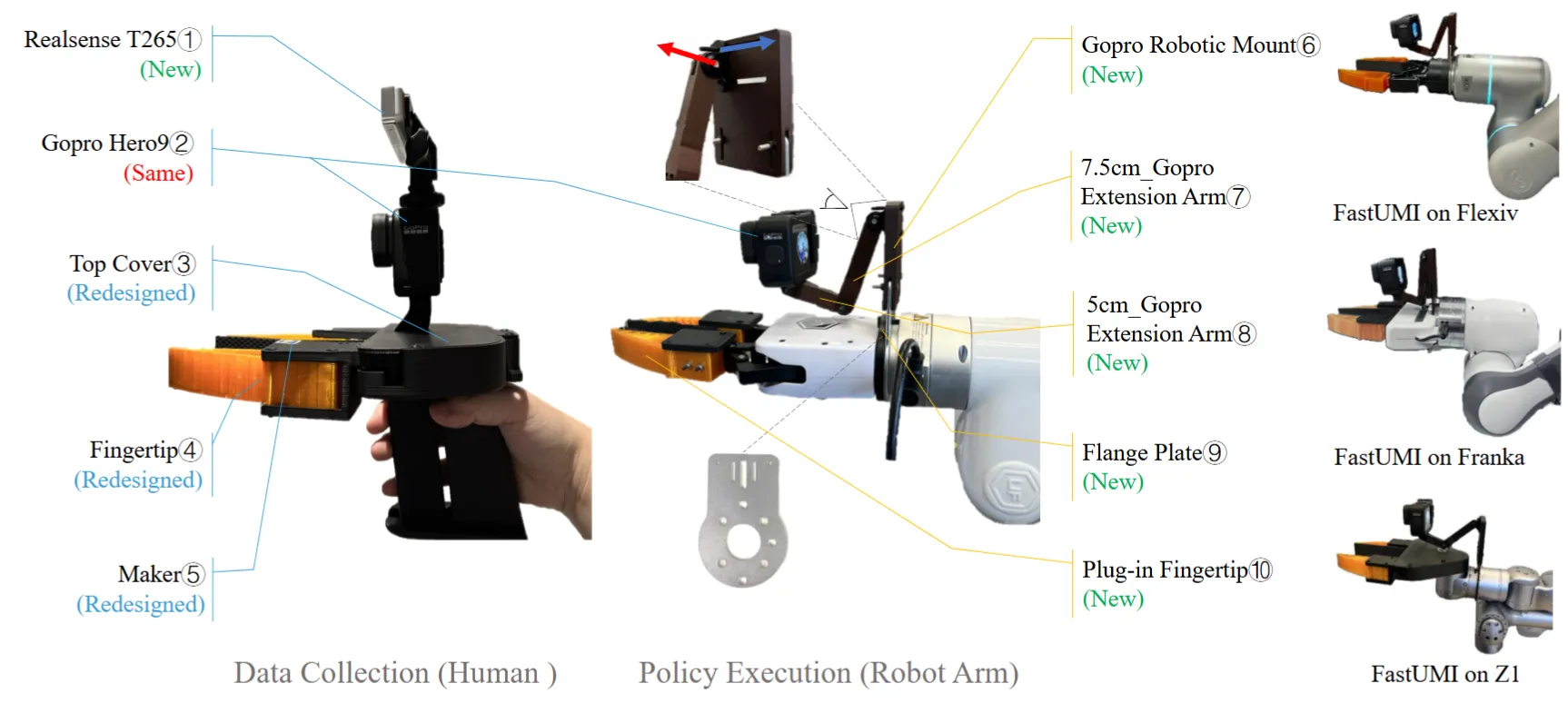
FastUMI 其实就是 UMI 的一个改版,优化了一些工程细节,并且提供了一个 10k 级别的数据集。其实我们不难看出,从实现上来说,FastUMI 和 UMI 的差异性体现出了他们思路上的区别。FastUMI 解耦了 Gripper 部分的实现,这使得任何一种本体都可以给 FastUMI 快速采集数据,在特定任务中微调;而 UMI 本身则控制 Gripper 部分的本体完全一致,这显然带来的好处是不同本体之间的数据更加统一,但是失去了一些灵活性。从我的角度上说,我支持更加 Scaling 的技术方案,因此或许是 UMI。
MV-UMI#
UMI,将第三人称的数据的人用管线消除掉
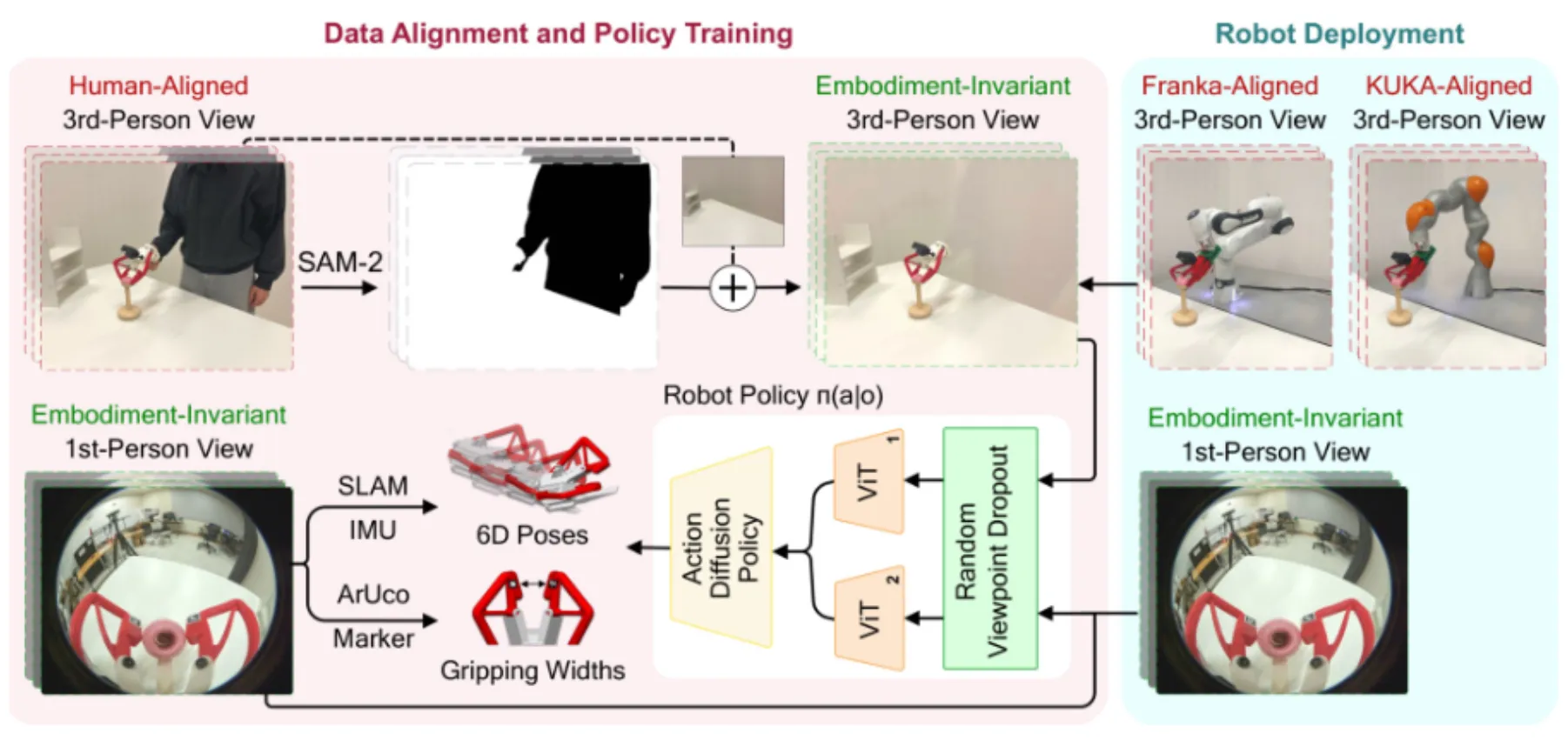
MV-UMI 如上所示,其实就是正常的 UMI,然后因为第三人称的数据也很重要,于是采集了一下,并且用 SAM2 把视角里的人消除掉了。本身比较无趣。
DexUMI#
同构手套 + SAM 抠图的灵巧手 UMI

DexUMI 的结构如上所示,其实就是做了一个和灵巧手本体同构的手套,然后让人可以操作。本身可能更多的还是机械结构上的设计,在这里就不过多赘述。
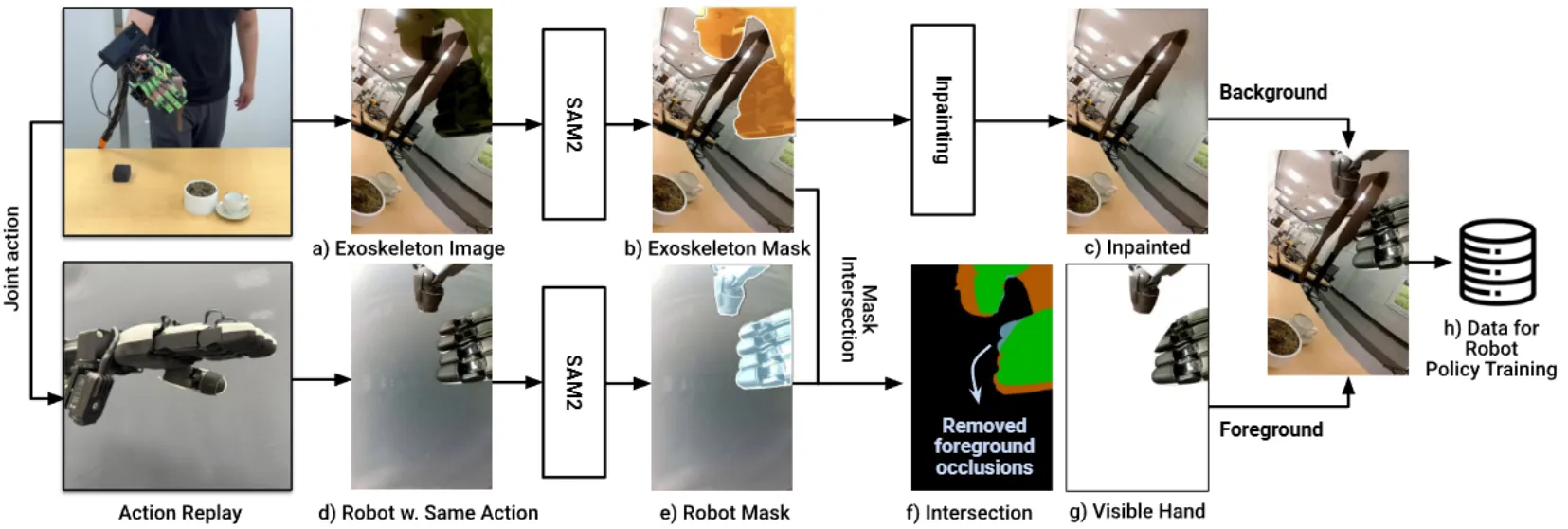
其中一个比较明显的问题肯定还是在于手套的视觉特征看上去和灵巧手本体还是不太一样,这里使用的方法就是,直接用 SAM 把手套扣掉,然后拼一个 Replay 的灵巧手上去。其实理论来说,假如说渲染效果足够好,感觉其实用渲染的灵巧手也是类似的效果,总体来说还是挺不错的。从工程量上还是充分的。
PEEK#
使用 VLM 在图片上 Mask 无关物体并标注轨迹后作为 Obs 接入常规 Policy
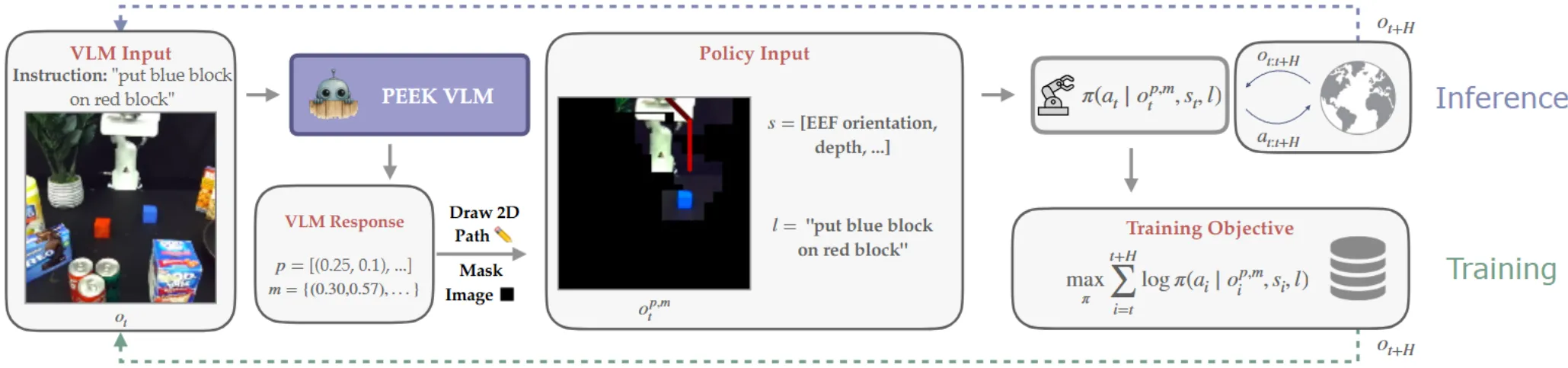
PEEK 的结构如上所示。基本上可以理解为,使用 PEEK VLM 来输出 Path 以及 Bounding Box,其中 Path 用颜色变化表示时间,这一点上和 RT-Trajectory 的思路是一致的。本身 PEEK 的 Insight 在于,使用 VLM 来 Mask 掉任务无关的物体,从而使得模型可以 focus 在相关物体上,这样即使说下游并没有学到真正的 object-level awareness,也依然是可以进行操作的。当然,这其中包括了不少问题,首先,并非端到端,这使得 VLM 不能被充分联合优化;其次,PEEK 本身的方案,和我直接将 BBox 也标注在图上是等效的,只是说这种 Mask 的方式更加直观一些,在大量数据上似乎并没有什么借鉴意义。同时,就像前面说到的一样,这种方式只会让模型尝试学到一种物体无关的 Skill,而并非真正意义上的 Zero-shot,思路上和之前的 MOO 其实高度一致。所以并没有很多的新 Insight。
VisualMimic#
通过训练 Teacher Student 结构来进行学习的 Locomotion
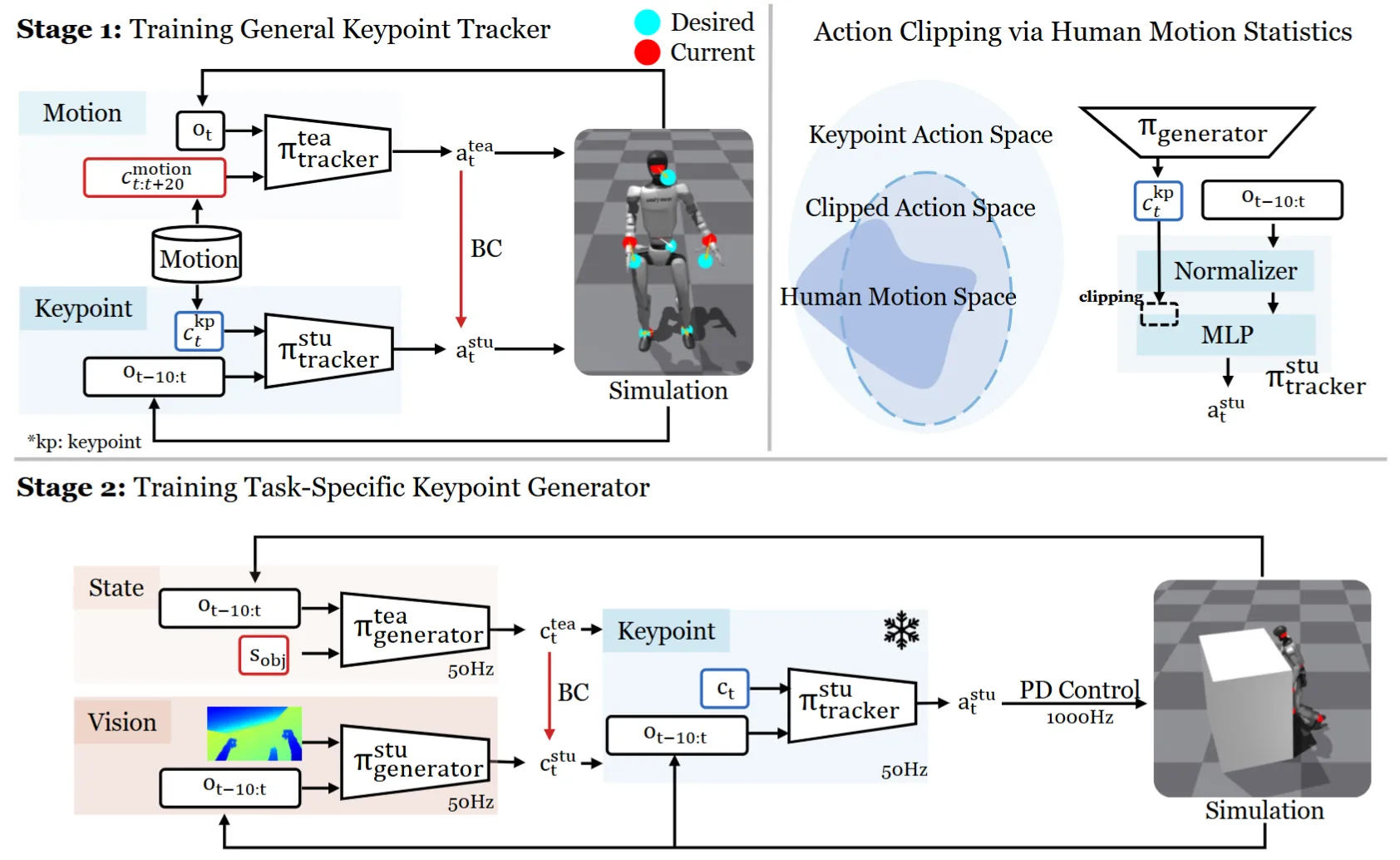
前情提要,此分数源于本人不熟悉此领域工作,所以不一定可以准确评估。
VisualMimic 本身算是从身体关键点学习机器人动作的工作。这其中主要包括的亮点有 Zero-shot sim2real 以及一些比较 fancy 的 task。本身 VisualMimic 其中在各种地方都使用了 Student-Teacher 的结构来学习,如图中所示。在第一阶段的过程中,Teacher 的优势在于可以获得到未来的点,从而更好地预测 Action,之后用 BC 让 Student 来学习。在第二阶段的过程中,Teacher 的优势在于可以获得到 object 的 state,而 student 则是视觉输入,之后用 BC 让 Student 来学习。这里第一阶段的一对 T-S 是预测 Action,之后将 stu 拿出来,作为第二段的关键点 to Action 的 Bridge,之后第二段的一组 T-S 则是输入 Obs 预测关键点。
这种一层层 Teacher-Student 的设计还是比较有意思的,这里的 concern 在于,没有联合优化的话(因为第二阶段的 c to a generator 是 frozen 的),会不会产生累积误差,还是说此时 generator 上游的 T-S 可以将错就错,在 generator 的 space 里面进行优化,还未可知。
villa-X#
使用 latent action 作为推理的中间表征的 Pi-like VLA
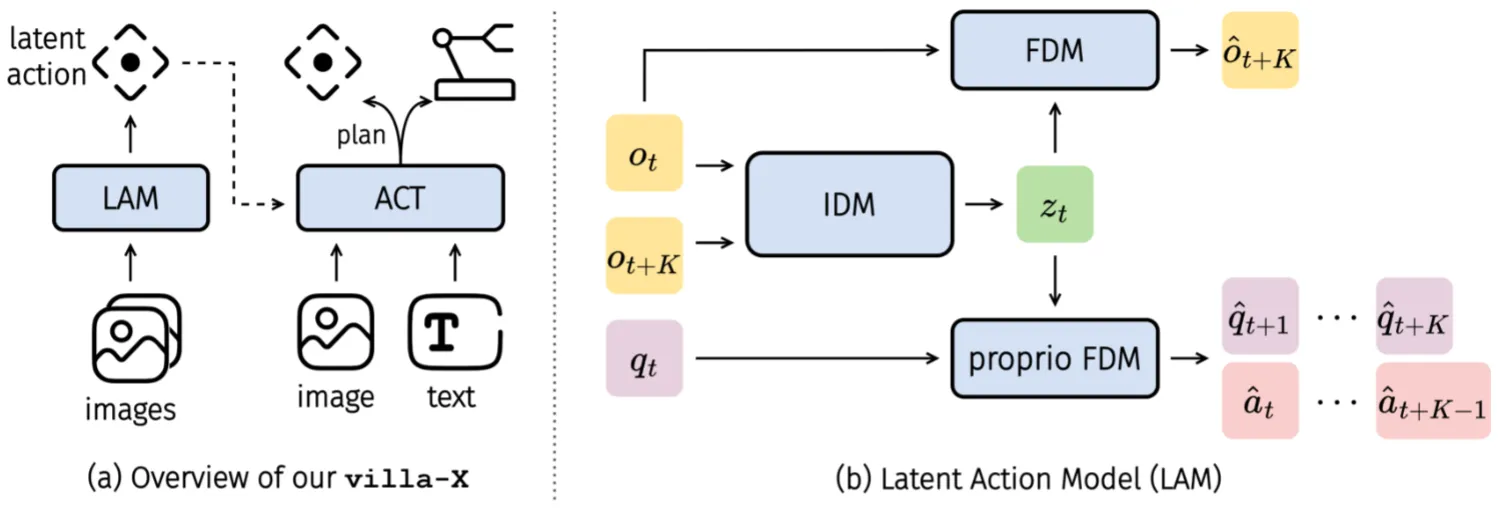
villa-X 的结构如上所示。本身还是 Pi-like 的范式,但是是三组 Transformer,分别是 VLM,Latent Action DP 以及 Action DP,其中 Latent Action 以及 Action 都是用 FM Loss 训练,并且整体用 MoT 的设计。这一设计奇怪的点在于,本身 Latent Action 已经表示了 Action 的信息,多加一层 Action 的 Transformer 似乎并没有必要,毕竟假如足够相信自己的 IDM,那么直接 Latent Action + MLP 其实就已经足够了。有必要使用一层 DP 可能就是因为依然精度问题有必要使用 Corse to Fine 导致的。
本身使用的 Trick 还包括注意力掩码值之类的,但是似乎没有进行相关的消融,不知道这些内容对于结果的提升是不是足够大,以及在各种消融中这些 Trick 是否都被应用。
RoLA#
使用图片重建场景的数据生成管线
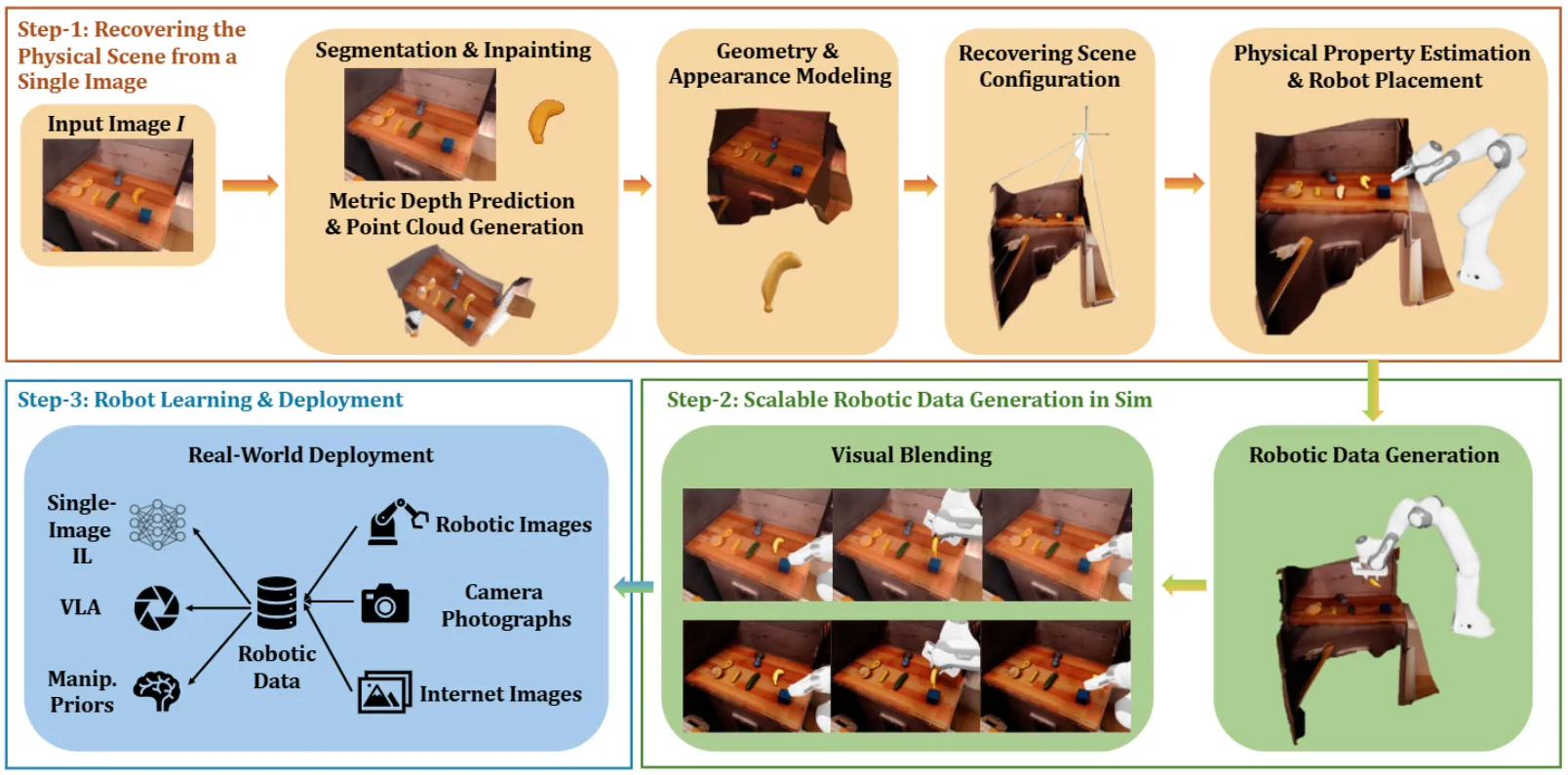
RoLA 实际上就是用 SAM 分割场景,每个部分进行重建,进而产生可交互的三维场景,再此之后使用仿真进行数据生成。其实本身的想法是好的,但是必然,使用这些方法一方面拉长了数据生成管线的长度,不可避免的是,可以产生一些 demo,但是在大规模 scaling 的时候生成优质数据的概率就会较低。同时也受到诸如 skill 等内容的限制。本质上来说,其实 RoLA 本身提出的只是一套场景资产生成策略。本身还算好玩。
InSpire#
使用空间推理的 OpenVLA-like VLA
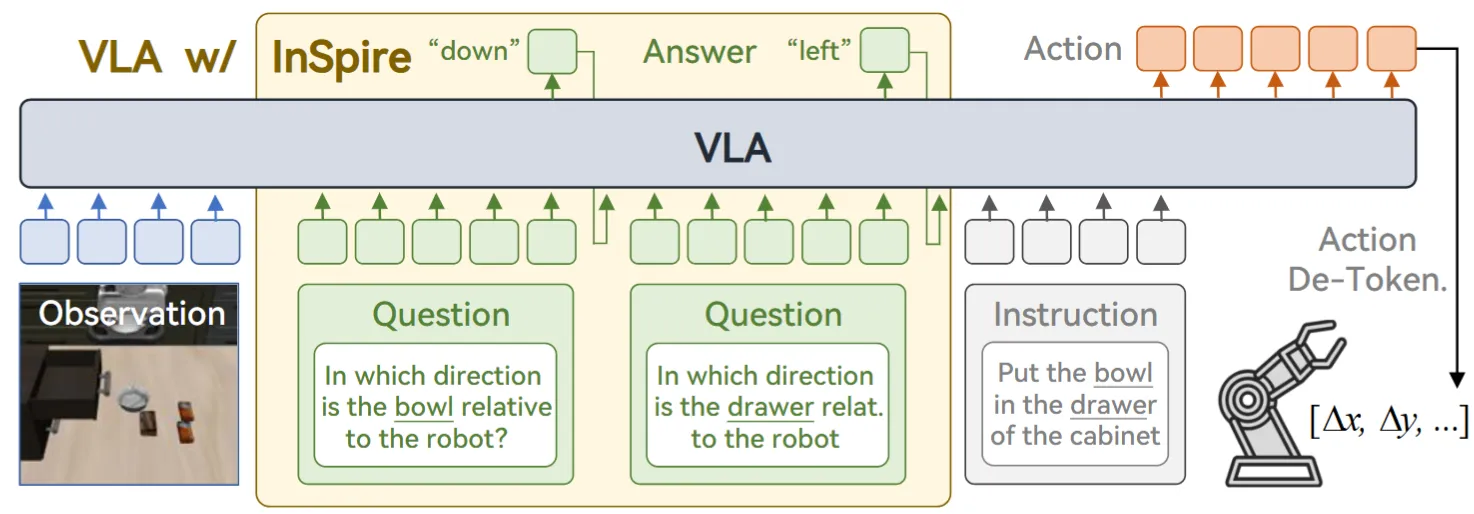
InSpire 的方法其实相当简单,如图中所示,就是在模型进行输出 Action 之前增加了几个问题,即相关物体相较于机器人的方位。从直觉上来说,这些推理问题并不是最优的让模型理解场景的方式,甚至说比如 BBox 或者其他的内容效果可能会更好,而且范式本身也是比较老旧的 OpenVLA-like 范式,所以感觉整体一般。
dVLA#
生成图片以及问题的 Diffusion VLA
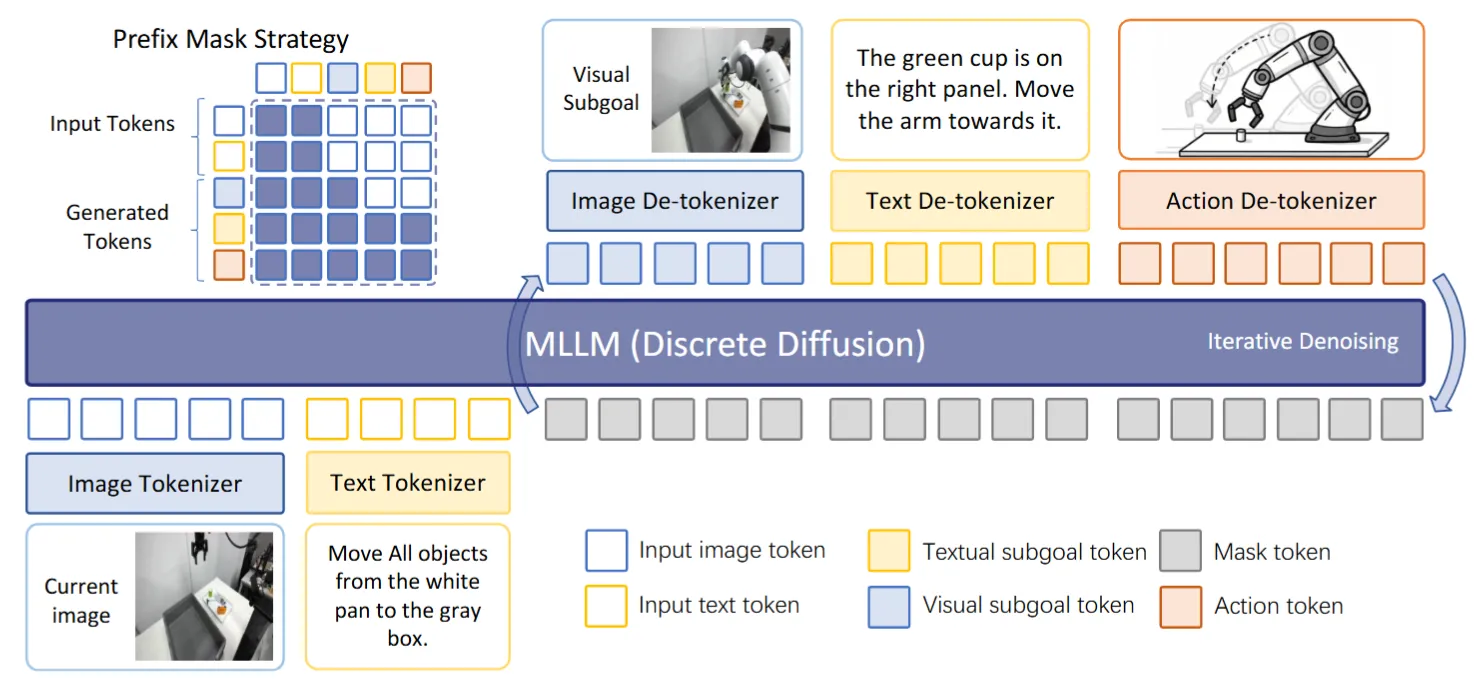
dVLA 做的事情本身还是比较直观,但是确实是第一个做得比较齐全的,并且看上去比较的工整,后续的工作在其上面加减法也是比较好的选择。本身 dVLA 就是使用 Diffusion VLM 来训练一个 VLA,这样子 Language/Image/Action 都是用 Diffusion 来生成,本身无论是速度还是说可以生成图片用图片进行推理,都是比较好的。这里面直接从 MMaDA 初始化,然后预测未来的 Image 以及描述场景来作为 CoT,之后输出 Action。相对简洁,不错。
RoboPilot#
使用快慢系统 Code as Policy 的 VLM Modular Framework
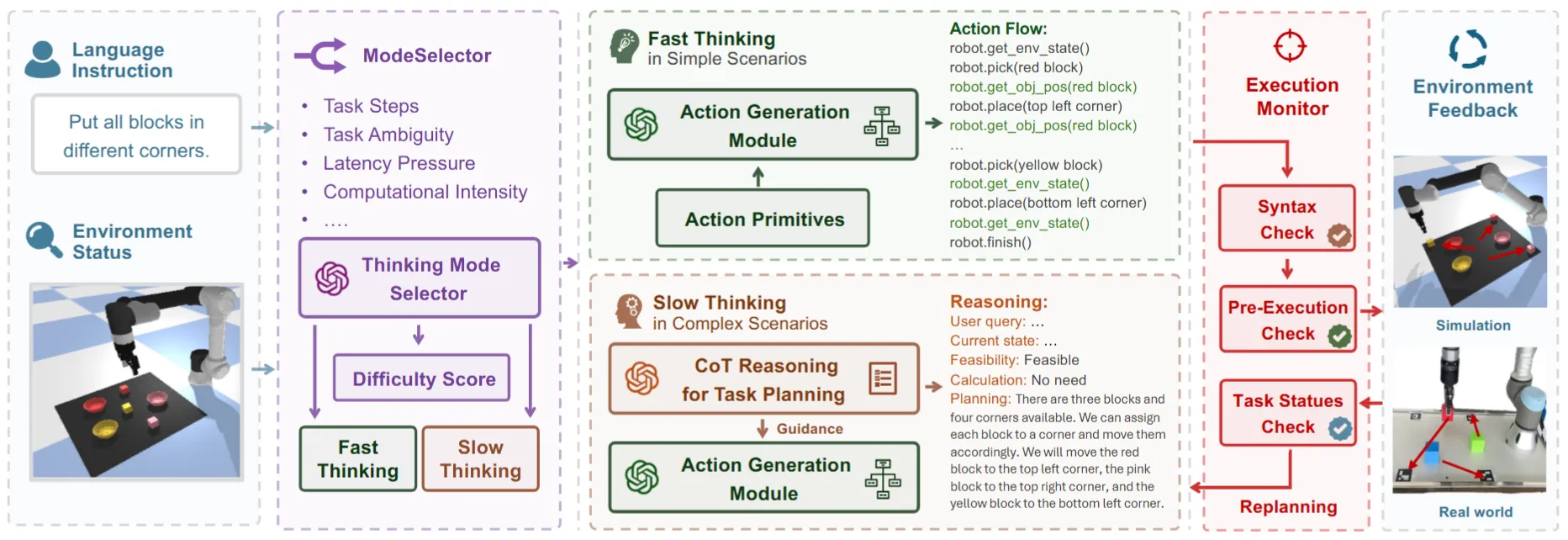
RoboPilot 的结构如上所示,本身还是使用快慢系统,其中快系统是 Code as Policy,慢系统是 Thinking,本身并没有什么特别的。本身当下 VLM 对于场景的感知能力其实还有所欠缺,之前的若干类似的 Modular Framework 都是使用了额外的工具来增强模型的能力,而不是直接使用 VLM 来搭建系统。所以综上还是比较平平无奇。
Gemini Robotics 1.5#
介绍了 Gemini 双系统结构,以及最新的一些模型效果
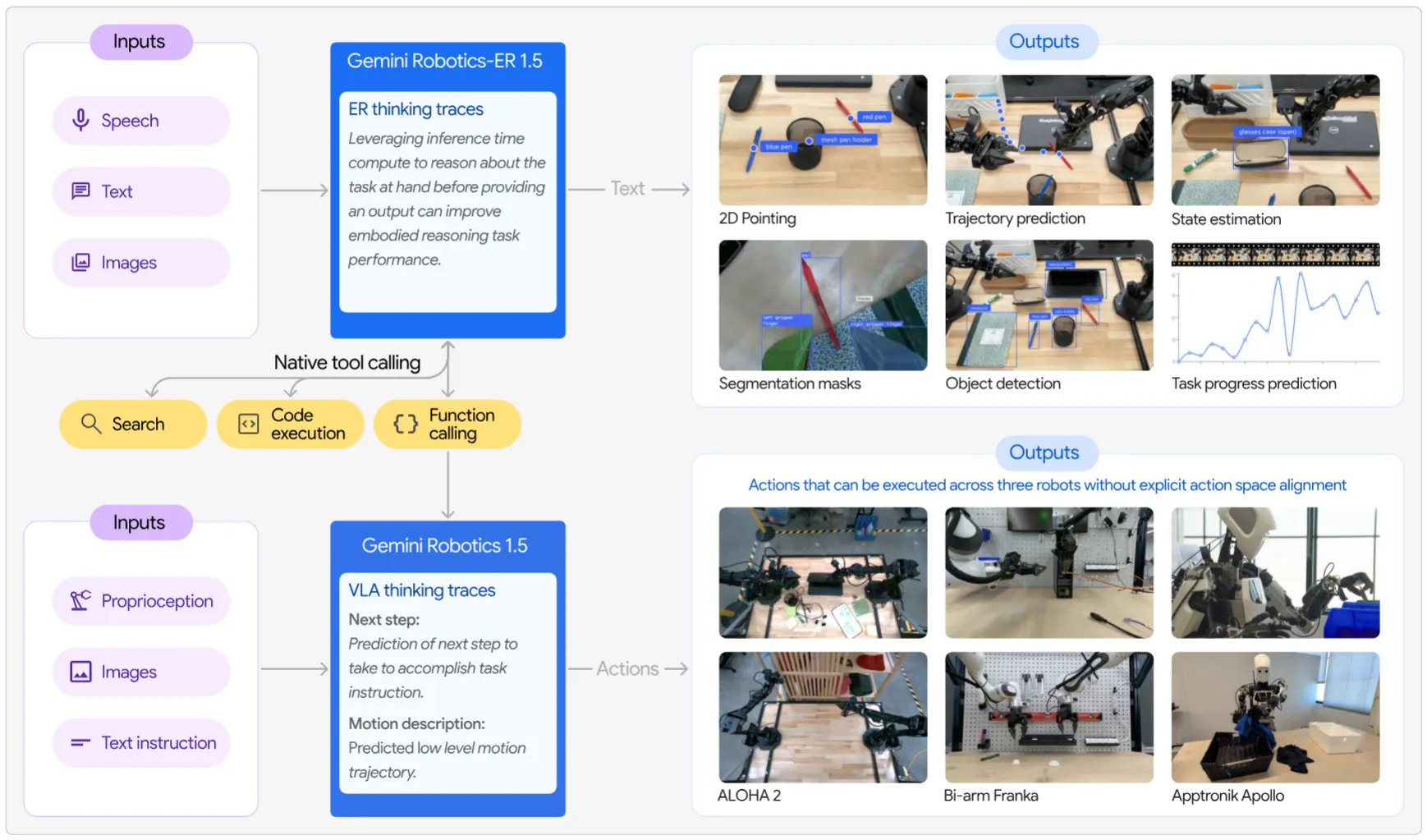
Gemini Robotics 的技术报告,本身的话并没有透露很多的技术细节。本身 Gemini Robotics 1.5 还是使用 VLM + VLA 的结构,这里面图中的内容其实比较有意思,将 VLA 定义为了一种 Function call,这种定义其实和一开始很久以前 1.0 的宣传视频的时候我们的分析比较一致。作为一个比较全面的 Code as Policy 的框架,可能这里面的 Function 还包括 Mask, BBox 或者 Point 的 tracking 之类的内容,伴随着不同频的推理来达到灵活的调用。其中部分的内容带来了一些其实意义不大的 Insight,但是还是提及一下。
首先,思考有助于行动,这里不只是单步的 Reasoning,也包括说,其表示,interleave 的方式效果会好很多,也就是一步一步 Reasoning subtasks。其次,他们的 MT 方案(似乎没有具体说如何做的)可以实现 cross-embodiment 的促进作用,这其实也体现了不同源轨迹多样的重要性。这里面值得一提的是,其表明,MT 通过对齐不同 embodiment 并提取共性,放大了这些数据的正向迁移作用,从而有助于学习过程。也就是数据中和 Inference 过程中同/相似特征的数据帮助更大。大概一共就是这些,作为大型的报告,还是狠狠秀了一波肌肉,包括 GR-ER 的具身推理能力也提升不错。